7.4. CSV Phones¶
7.4.1. Case Study - 0x01¶
import pandas as pd
from matplotlib import pyplot as plt
pd.set_option('display.width', 300)
pd.set_option('display.max_columns', 25)
pd.set_option('display.max_rows', 100)
pd.set_option('display.min_rows', 100)
pd.set_option('display.max_seq_items', 100)
MONTHS = [
'January', 'February', 'March', 'April',
'May', 'June', 'July', 'August', 'September',
'October', 'November', 'December',
]
df = (pd
.read_csv(
filepath_or_buffer='https://python3.info/_static/phones-pl.csv',
parse_dates=['datetime'])
.assign(
date=lambda df: df['datetime'].dt.date,
time=lambda df: df['datetime'].dt.time,
year=lambda df: df['period'].str.split('-', expand=True)[0],
month=lambda df: df['period'].str.split('-', expand=True)[1],
weekday=lambda df: df['datetime'].dt.strftime('%A'))
.set_index(keys='datetime', drop=True)
.drop(columns=['id'])
.convert_dtypes()
.astype({'month': int})
.replace({'month': dict(enumerate(MONTHS, start=1))})
.groupby(['period','item', 'network'])
.aggregate(
duration_count=('duration', 'count'),
duration_sum=('duration', 'sum'),
duration_mean=('duration', 'mean'),
duration_std=('duration', 'std'),
duration_var=('duration', 'var'),
duration_min=('duration', 'min'),
duration_q25=('duration', lambda column: column.quantile(.25)),
duration_q50=('duration', lambda column: column.quantile(.50)),
duration_q75=('duration', lambda column: column.quantile(.75)),
duration_max=('duration', 'max'),
duration_skew=('duration', 'skew'),)
.convert_dtypes()
.round(decimals=2)
)
# %%
data = (
df
.xs('sms', level=1)
.loc[:, 'duration_count']
.droplevel(1)
).plot(
legend=True,
grid=True,
figsize=(16,10),
title='Number of SMS in given period',
ylabel='Number of SMS',
xlabel='Timeframe',
)
# plt.show()
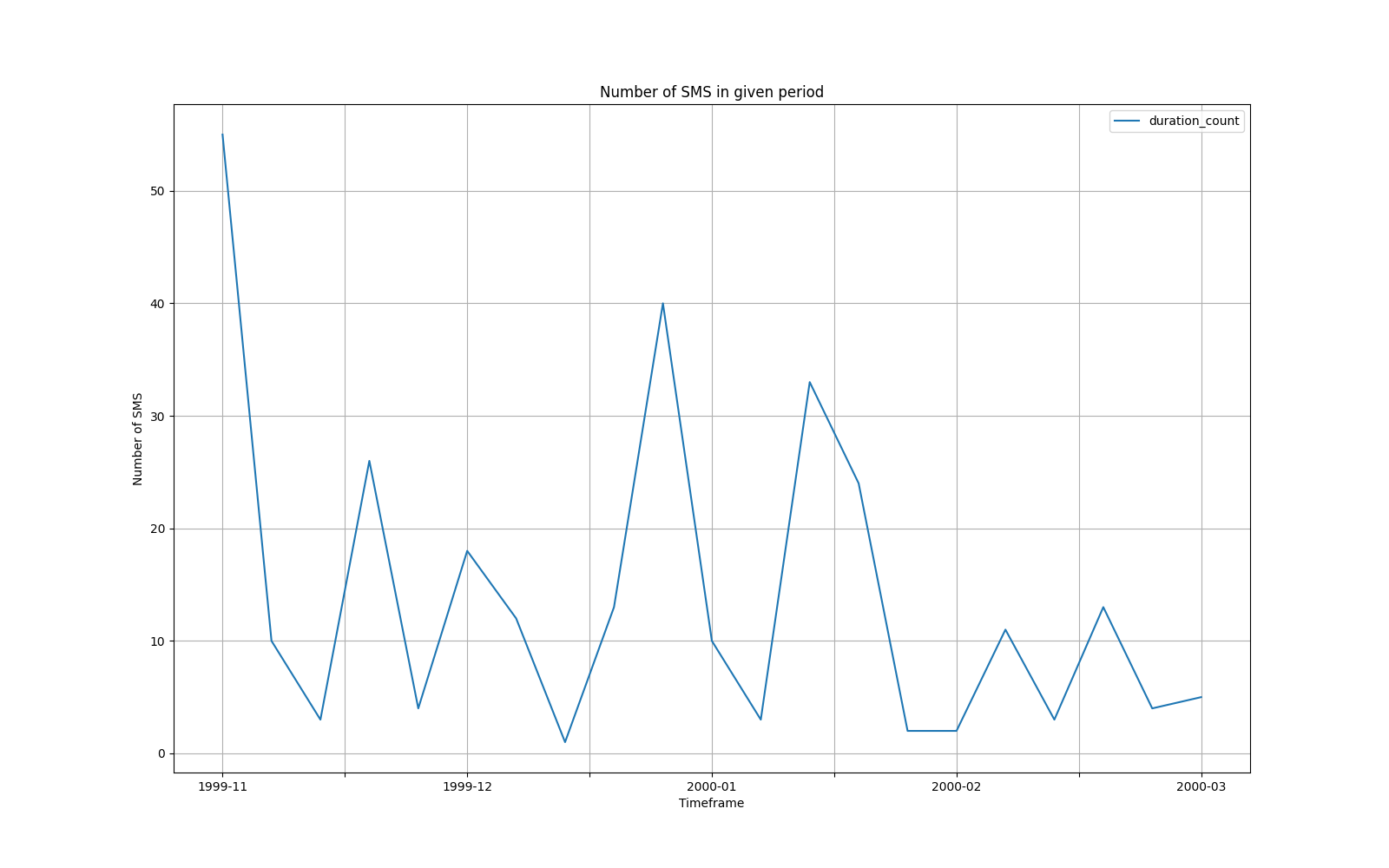
Figure 7.9. Number of SMS in given period¶
7.4.2. Case Study - 0x02¶
import pandas as pd
from timeit import timeit
from matplotlib import pyplot as plt
from pandas.tseries.holiday import AbstractHolidayCalendar, Holiday, EasterMonday, Easter
from pandas.tseries.offsets import Day
pd.set_option('display.width', 300)
pd.set_option('display.max_columns', 25)
pd.set_option('display.max_rows', 100)
pd.set_option('display.min_rows', 100)
pd.set_option('display.max_seq_items', 100)
class PLHolidayCalendar(AbstractHolidayCalendar):
"""
Custom Holiday calendar for Poland based on
https://en.wikipedia.org/wiki/Public_holidays_in_Poland
"""
rules = [
Holiday('New Years Day', month=1, day=1),
Holiday('Epiphany', month=1, day=6),
Holiday('Easter', month=1, day=1, offset=[Easter()]),
EasterMonday,
Holiday('May Day', month=5, day=1),
Holiday('Constitution Day', month=5, day=3),
Holiday('Pentecost Sunday', month=1, day=1, offset=[Easter(), Day(49)]),
Holiday('Corpus Christi', month=1, day=1, offset=[Easter(), Day(60)]),
Holiday('Assumption of the Blessed Virgin Mary', month=8, day=15),
Holiday('All Saints Day', month=11, day=1),
Holiday('Independence Day', month=11, day=11),
Holiday('Christmas Day', month=12, day=25),
Holiday('Second Day of Christmastide', month=12, day=26),
]
DATA = 'https://python3.info/_static/phones-pl.csv'
df = (pd
.read_csv(DATA, parse_dates=['datetime'])
.assign(
date = lambda df: df['datetime'].dt.date,
time = lambda df: df['datetime'].dt.time,
year = lambda df: df['datetime'].dt.year,
month = lambda df: df['datetime'].dt.strftime('%B'),
weekday = lambda df: df['datetime'].dt.strftime('%A'))
.drop(columns=['id'])
.set_index('datetime', drop=True)
.convert_dtypes()
)
duration = timeit('pd.read_csv(DATA)', globals=globals(), number=1)
print(f'Data read took {duration:.4f} seconds')
df.info(memory_usage='deep')
df.describe()
# Aggregate
report = df.groupby(['period', 'item']).aggregate(
duration_count = ('duration', 'count'),
duration_sum=('duration', 'sum'),
duration_mean = ('duration', 'mean'),
duration_std = ('duration', 'std'),
duration_var = ('duration', 'var'),
duration_min = ('duration', 'min'),
duration_q25 = ('duration', lambda column: column.quantile(.25)),
duration_q50 = ('duration', lambda column: column.quantile(.50)),
duration_q75 = ('duration', lambda column: column.quantile(.75)),
duration_max = ('duration', 'max'),
duration_skew=('duration', 'skew'),
date_first = ('date', 'first'),
date_last = ('date', 'last'),
).round(1)
# W jakim `period` było najwięcej połączeń telefonicznych `item==call`
report.xs('call', level='item')['duration_count'].index[0]
# w jakich okresach było więcej smsów niż średnia
sms = report.xs('sms', level='item')
mean = sms['duration_sum'].mean()
query = sms['duration_sum'] > mean
result = list(sms[query].index) # ['1999-11', '2000-01']
# Jaka sieć telefoniczna miała najwięcej przetransferowanych data
result = (df
.query('type=="data"')
.groupby('network')['duration']
.sum()
.sort_values(ascending=False)
.index[0]
)
# Pokaż mi ile było call, data, sms w okresie gwiazdki (24, 25, 26 grudnia)
df.loc['1999-12-24':'1999-12-26', ['item','duration']].groupby('item').count()
# Pokaż mi ile było call, data, sms w okresie 5 dni po wielkanocy 2000
easter = PLHolidayCalendar().rule_from_name('Easter').dates(start_date='2000-01-01', end_date='2000-12-31')[0] # Timestamp('2000-04-23 00:00:00')
easter = pd.Timestamp('2000-03-01') # Ponieważ poprzednia data w danych nie występuje, przyjmijmy, że wielkanoc była 1 marca (tylko dla przykładu)
result = df.query('index > @easter').first('5d').loc[:, ['item','duration']].groupby('item').count()