2.5. Glossary¶
- Accuracy (error rate)¶
The rate of correct (incorrect) predictions made by the model over a data set (cf. coverage). Accuracy is usually estimated by using an independent test set that was not used at any time during the learning process. More complex accuracy estimation techniques, such as cross-validation and the bootstrap, are commonly used, especially with data sets containing a small number of instances.
- Association learning¶
Techniques that find conjunctive implication rules of the form "\(X\) and \(Y\) implies \(A\) and \(B\) " (associations) that satisfy given criteria. The conventional association algorithms are sound and complete methods for finding all associations that satisfy criteria for minimum support (at least a specified fraction of the instances must satisfy both sides of the rule) and minimum confidence (at least a specified fraction of instances satisfying the left hand side, or antecedent, must satisfy the right hand side, or consequent).
- Attribute (field, variable, feature)¶
A quantity describing an instance. An attribute has a domain defined by the attribute type, which denotes the values that can be taken by an attribute. The following domain types are common:
- Categorical
A finite number of discrete values. The type nominal denotes that there is no ordering between the values, such as last names and colors. The type ordinal denotes that there is an ordering, such as in an attribute taking on the values low, medium, or high.
- Continuous (quantitative)
Commonly, subset of real numbers, where there is a measurable difference between the possible values. Integers are usually treated as continuous in practical problems.
A feature is the specification of an attribute and its value. For example, color is an attribute. "Color is blue" is a feature of an example. Many transformations to the attribute set leave the feature set unchanged (for example, regrouping attribute values or transforming multi-valued attributes to binary attributes). Some authors use feature as a synonym for attribute (e.g., in feature-subset selection).
- Classification¶
Process related to categorization, the process in which ideas and objects are recognized, differentiated, and understood.
- Classifier¶
A mapping from unlabeled instances to (discrete) classes. Classifiers have a form (e.g., decision tree) plus an interpretation procedure (including how to handle unknowns, etc.). Some classifiers also provide probability estimates (scores), which can be threshold to yield a discrete class decision thereby taking into account a utility function.
- Cluster¶
Group of loosely coupled objects that belongs to the same category
- Confusion matrix¶
A matrix showing the predicted and actual classifications. A confusion matrix is of size \(LxL\) , where L is the number of different label values. The following confusion matrix is for \(L=2\) :
actual / predicted
negative
positive
Negative
a
b
Positive
c
d
The following terms are defined for a two by two confusion matrix:
- Accuracy
\((a+d) / (a+b+c+d)\)
- True positive rate (Recall, Sensitivity)
\(d / (c+d)\)
- True negative rate (Specificity)
\(a / (a+b)\)
- Precision
\(d / (b+d)\)
- False positive rate
\(b / (a+b)\)
- False negative rate
\(c / (c+d)\)
- Coverage¶
The proportion of a data set for which a classifier makes a prediction. If a classifier does not classify all the instances, it may be important to know its performance on the set of cases for which it is "confident" enough to make a prediction.
- Cost (utility/loss/payoff)¶
A measurement of the cost to the performance task (and/or benefit) of making a prediction Y' when the actual label is y. The use of accuracy to evaluate a model assumes uniform costs of errors and uniform benefits of correct classifications.
- Cross-validation¶
A method for estimating the accuracy (or error) of an inducer by dividing the data into k mutually exclusive subsets (the "folds") of approximately equal size. The inducer is trained and tested \(k\) times. Each time it is trained on the data set minus a fold and tested on that fold. The accuracy estimate is the average accuracy for the k folds.
- Data cleaning/cleansing¶
The process of improving the quality of the data by modifying its form or content, for example by removing or correcting data values that are incorrect. This step usually precedes the machine learning step, although the knowledge discovery process may indicate that further cleaning is desired and may suggest ways to improve the quality of the data. For example, learning that the pattern Wife implies Female from the census sample at UCI has a few exceptions may indicate a quality problem.
- Data mining¶
The term data mining is somewhat overloaded. It sometimes refers to the whole process of knowledge discovery and sometimes to the specific machine learning phase.
- Data set¶
A schema and a set of instances matching the schema. Generally, no ordering on instances is assumed. Most machine learning work uses a single fixed-format table.
- Decision Boundary¶
In a statistical-classification problem with two classes, a decision boundary or decision surface is a hyper-surface that partitions the underlying vector space into two sets, one for each class. The classifier will classify all the points on one side of the decision boundary as belonging to one class and all those on the other side as belonging to the other class.
A decision boundary is the region of a problem space in which the output label of a classifier is ambiguous.
- Dimension¶
An attribute or several attributes that together describe a property. For example, a geographical dimension might consist of three attributes: country, state, city. A time dimension might include 5 attributes: year, month, day, hour, minute.
- Discriminative model¶
Class of models used in machine learning for modeling the dependence of unobserved (target) variables \(y\) on observed variables \(x\). Within a probabilistic framework, this is done by modeling the conditional probability distribution \(P(y|x)\), which can be used for predicting \(y\) from \(x\).
Discriminative models, as opposed to generative models, do not allow one to generate samples from the joint distribution of observed and target variables. However, for tasks such as classification and regression that do not require the joint distribution, discriminative models can yield superior performance (in part because they have fewer variables to compute). On the other hand, generative models are typically more flexible than discriminative models in expressing dependencies in complex learning tasks. In addition, most discriminative models are inherently supervised and cannot easily support unsupervised learning. Application-specific details ultimately dictate the suitability of selecting a discriminative versus generative model.
- Error rate¶
See Accuracy.
- Example¶
See Instance.
- Feature¶
See Attribute.
- Feature vector (record, tuple)¶
A list of features describing an instance.
- Field¶
See Attribute.
- Generative Model¶
In statistical classification, including machine learning, two main approaches are called the generative approach and the discriminative approach. These compute classifiers by different approaches, differing in the degree of statistical modelling. Terminology is inconsistent,[a] but three major types can be distinguished, following (Jebara 2004):
Given an observable variable \(X\) and a target variable \(Y\), a generative model is a statistical model of the joint probability distribution on \(X × Y\), \(P(X,Y)\),
A discriminative model is a model of the conditional probability of the target \(Y\), given an observation \(x\), symbolically, \(P(Y|X=x)\),
Classifiers computed without using a probability model are also referred to loosely as "discriminative".
- i.i.d. sample¶
A set of independent and identically distributed instances.
- Inducer / induction algorithm¶
An algorithm that takes as input specific instances and produces a model that generalizes beyond these instances.
- Instance (example, case, record)¶
A single object of the world from which a model will be learned, or on which a model will be used (e.g., for prediction). In most machine learning work, instances are described by feature vectors; some work uses more complex representations (e.g., containing relations between instances or between parts of instances).
- Knowledge discovery¶
The non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data. This is the definition used in "Advances in Knowledge Discovery and Data Mining", 1996, by Fayyad, Piatetsky-Shapiro, and Smyth.
- Learning Algorithm¶
Procedure that creates classifiers. Finds patterns in training data.
- Loss¶
See Cost.
- Machine learning¶
In Knowledge Discovery, machine learning is most commonly used to mean the application of induction algorithms, which is one step in the knowledge discovery process. This is similar to the definition of empirical learning or inductive learning in Readings in Machine Learning by Shavlik and Dietterich. Note that in their definition, training examples are "externally supplied", whereas here they are assumed to be supplied by a previous stage of the knowledge discovery process. Machine Learning is the field of scientific study that concentrates on induction algorithms and on other algorithms that can be said to "learn".
- Missing value¶
The value for an attribute is not known or does not exist. There are several possible reasons for a value to be missing, such as: it was not measured; there was an instrument malfunction; the attribute does not apply, or the attribute's value cannot be known. Some algorithms have problems dealing with missing values.
- Model¶
- Estimator¶
A structure and corresponding interpretation that summarizes or partially summarizes a set of data, for description or prediction. Most inductive algorithms generate models that can then be used as classifiers, as regressors, as patterns for human consumption, and/or as input to subsequent stages of the KDD process.
- Model deployment¶
The use of a learned model. Model deployment usually denotes applying the model to real data.
- Observation¶
One row in features and labels table. For example Iris dataset has 150 observations.
- Out-of-sample data¶
Data that is not in Observation. In most cases that would be the data to predict.
- OLAP (MOLAP, ROLAP)¶
On-Line Analytical Processing. Usually synonymous with MOLAP (multi-dimensional OLAP). OLAP engines facilitate the exploration of data along several (predetermined) dimensions. OLAP commonly uses intermediate data structures to store pre-calculated results on multidimensional data, allowing fast computations. ROLAP (relational OLAP) refers to performing OLAP using relational databases.
- Overfitting¶
Models that overfit learns to recognize noise from the signal, than the data.
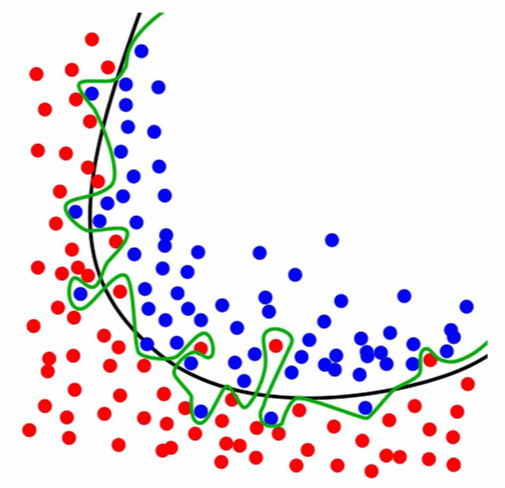
Figure 2.33. Black line represents the decision boundary and represents the signal. Green line represents overfitted model which learned the noise.¶
- Preprocessing¶
Is the module used to do some cleaning/scaling of data prior to machine learning.
- Record¶
See Feature vector.
- Regression¶
Is a form of supervised machine learning, which is where the scientist teaches the machine by showing it features and then showing it was the correct answer is, over and over, to teach the machine. Once the machine is taught, the scientist will usually "test" the machine on some unseen data, where the scientist still knows what the correct answer is, but the machine doesn't. The machine's answers are compared to the known answers, and the machine's accuracy can be measured. If the accuracy is high enough, the scientist may consider actually employing the algorithm in the real world.
- Regressor¶
A mapping from unlabeled instances to a value within a predefined metric space (e.g., a continuous range).
- Resubstitution accuracy (error/loss)¶
The accuracy (error/loss) made by the model on the training data.
- Schema¶
A description of a data set's attributes and their properties.
- Sensitivity¶
True positive rate (see Confusion matrix).
- Specificity¶
True negative rate (see Confusion matrix).
- Supervised learning¶
Techniques used to learn the relationship between independent attributes and a designated dependent attribute (the label). Most induction algorithms fall into the supervised learning category.
- Tuple¶
See Feature vector.
- Unsupervised learning¶
Learning techniques that group instances without a pre-specified dependent attribute. Clustering algorithms are usually unsupervised.
- Utility¶
See Cost.